Kunstig intelligens:

Maskinlæring på (nettverks)kanten
Hva kan sette fart på implementering av kunstig intelligens (AI)? I denne artikkelen tar vi for oss noen momenter.
Denne artikkelen er 2 år eller eldre
Kunstig intelligens er blitt noe alle innen bransjen må forholde seg til. Men hva, og hvordan?
Dagens behov for AI og ML
Kunstig intelligens (AI) og maskinlæring (ML) brukes i mange applikasjoner, i så forskjellige bransjer som reise, bank og finansielle tjenester, produksjon, matteknologi, helsevesen, logistikk, transport, underholdning og mange flere.
En av de velkjente applikasjonene er innen autonom kjøring, hvor bilen kan bruke maskinlæring til å gjenkjenne barrierer, fotgjengere og andre biler. Andre bruksområder inkluderer å forutsi eller oppdage sykdommer, og inspisere kretskort.
Hva kan sette fart på implementering av AI?
En av nøkkelfaktorene som akselererer AI- og ML-implementering er veksten i datakraft som gjør at komplekse matematikkberegninger kan utføres enkelt og raskt.
Det er også økende antall algoritmer som hjelper til med å lage modeller og gjør datainferens enklere og raskere. Både offentlige myndigheter og selskaper satser dessuten tungt på dette området.
AI/ML-verktøyene som hjelper de som ikke er dataeksperter til enkelt å forstå, lage og distribuere modeller er et avgjørende element, og er i dag mer og mer tilgjengelig og anvendelig.
Selv om modellbygging vil bli gjort i skyen på kraftige maskiner, vil vi ofte ønske å gjøre inferens lokalt. Dette har flere fordeler, inkludert økt sikkerhet fordi vi ikke kommuniserer til omverdenen. Å agere lokalt betyr at vi ikke bruker båndbredde og ikke betaler ekstra penger for å sende dataene til skyen for deretter å få resultatene tilbake.
Noen av fordelene ved å utføre inferens i nettverkskanten:
· Sanntidsoperasjon/Øyeblikkelig respons
- Lav forsinkelse, sikker drift
· Reduserte kostnader
- Effektiv bruk av nettverksbåndbredde, mindre kommunikasjon
· Pålitelig drift med intermitterende tilkobling
· Bedre kundeopplevelse
- Raskere responstid
· Personvern og sikkerhet
- Mindre data som skal overføres fører til bedre personvern
· Lavere effektforbruk
- Ikke behov for rask kommunikasjon
· Lokal læring
- Bedre ytelse ved å gjøre hvert enkelt produkt i stand til å lære individuelt
Latens, eller forsinkelse, er en god driver for å utføre inferens lokalt, fordi vi ikke venter på at informasjonen skal sendes og resultatene sendes tilbake. Nettverkskanten kan hjelpe brukere ved å flytte maskinlæring fra høyytelsesmaskiner til avanserte mikrokontrollere og avanserte mikroprosessorenheter.
Hva er kunstig intelligens og maskinlæring?
Kunstig intelligens ble etablert på 1950-tallet. I hovedsak erstatter AI programmeringsprosedyren ved å utvikle algoritmer basert på dataene, i stedet for den tradisjonelle metoden for å skrive dem manuelt. Maskinlæring er en undergruppe av kunstig intelligens, der maskinen prøver å trekke ut kunnskap fra dataene. Vi forsyner maskinen med forberedte data og ber den deretter komme opp med en algoritme som vil hjelpe til med å forutsi resultatene for nye ferske datasett.
ML er basert på det vi kaller «veiledet læring». I denne teknikken blir dataene merket, og resultatene er basert på den merkingen – vi bygger også modellen basert på den merkingen. En annen teknikk er dyp læring, som fungerer på mer komplekse algoritmer, hvor dataene ikke er merket. Vi vil i denne artikkelen hovedsakelig vurdere veiledet læring for kanten.
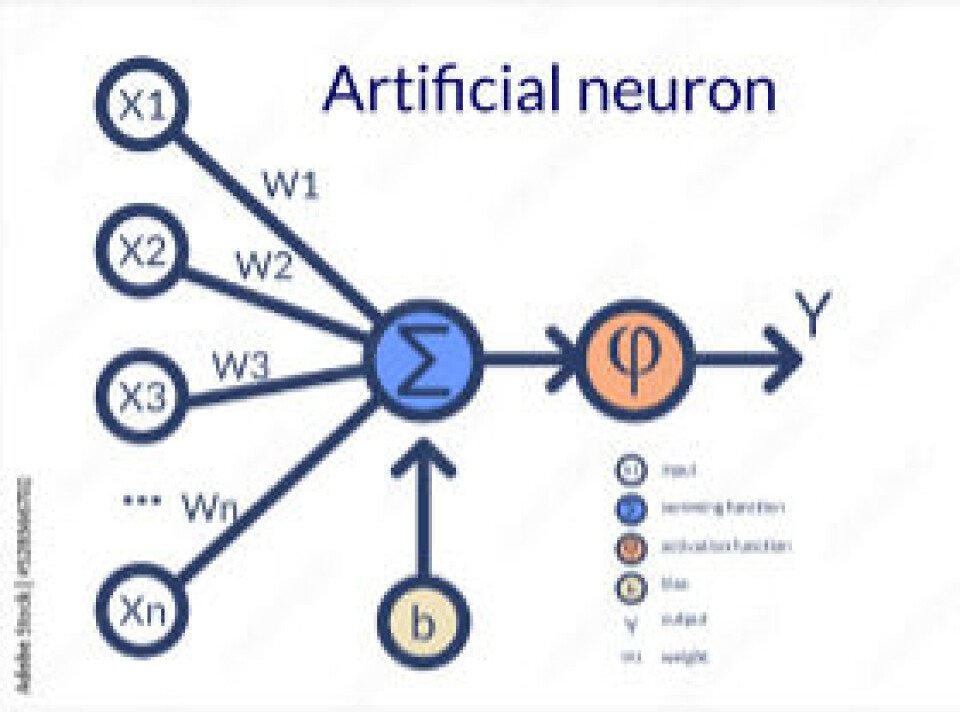
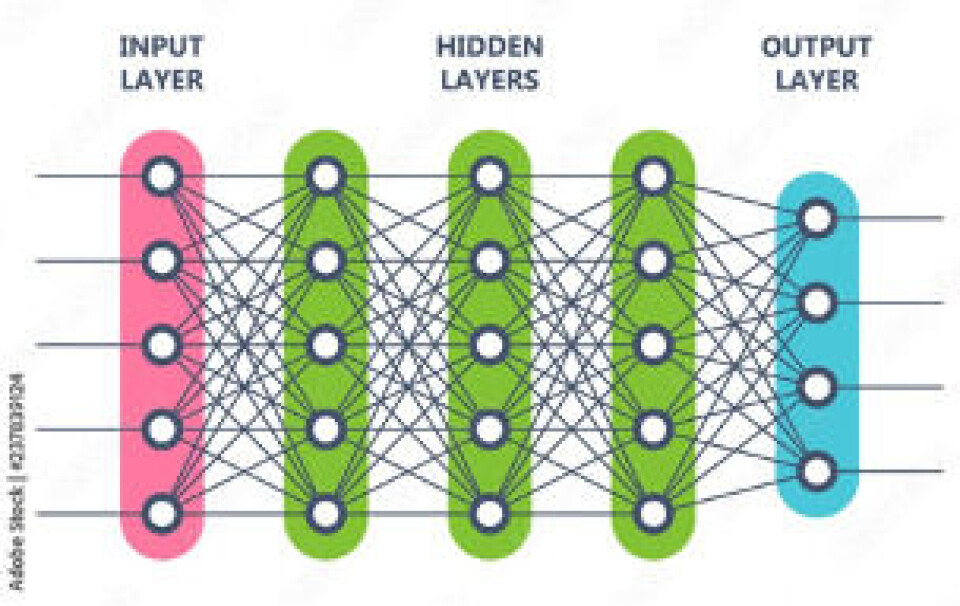
Nevrale nettverk
Grunnelementet i ML er det nevrale nettverket, som består av lag med noder, der hver node har en forbindelse til enten inngangene eller til de neste lagene. Det finnes flere typer nevrale nettverk. Jo mer vi beveger oss fra maskinlæring til dyp læring, jo mer vil vi se komplekse nettverk. Dyplæring inkluderer også noen tilbakemeldingsmekanismer, mens enkle ML-modeller har enkle fremadrettede handlinger, og beveger seg fra data til utdata eller resultat.
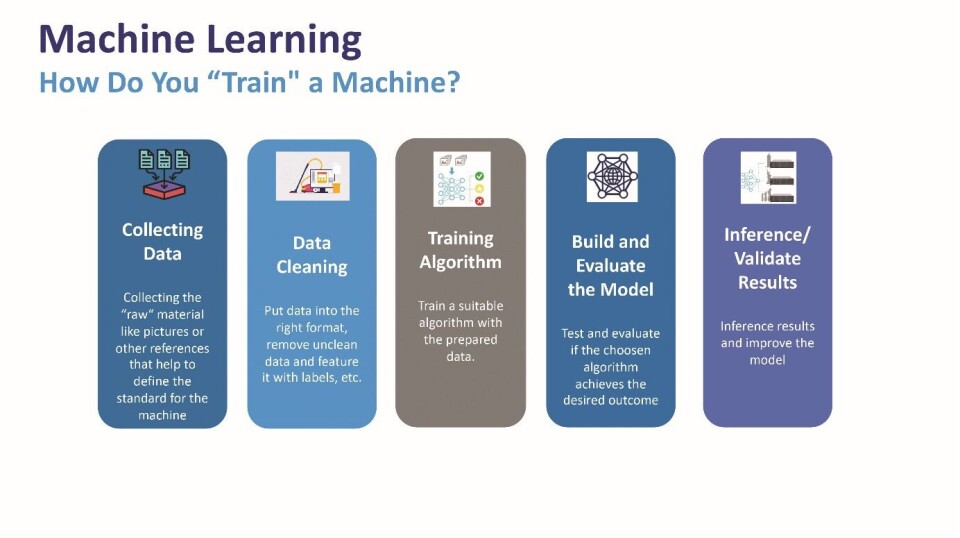
Hvordan kan du «trene» en maskin?
Det første trinnet er datainnsamling. Ettersom vi fokuserer på veiledet læring, samler vi inn merkede data, slik at mønstre kan bli funnet på riktig måte. Kvaliteten på disse dataene vil avgjøre hvor nøyaktig modellen er. Vi må sette den sammen og gjøre det tilfeldig. Hvis det er for organisert, vil ikke modeller lages riktig, og vi kan ende opp med dårlige algoritmer.
Trinn nummer to er å rense og fjerne uønskede data. Ethvert sett der noen futures mangler bør fjernes. Eventuelle tilstander der dataene ikke er nødvendige eller tilstander som vanligvis er ukjente, bør også fjernes.
Data må deretter deles i to deler, en for trening og den andre for testing.
Det tredje trinnet er å trene opp algoritmen. Dette er delt opp i tre trinn. Det første trinnet er å velge maskinlæringsklassifiseringsalgoritmen. Flere er tilgjengelige og passer til ulike typer data.
Eksempler på klassifiseringsalgoritmer for maskinlæring er:
· Bonsai
· Decision Tree Ensemble
· Boosted Tree Ensemble
· TensorFlow Lite for Microcontrollers (rammeverk)
· PME
Det er viktig å velge riktig modellsammensetning da dette bestemmer utdataene du får etter å ha kjørt ML-algoritmen på de innsamlede dataene. Dette kan trenge noen dataforskerferdigheter, men kan også overlates til den automatiske motoren som tilbys av flere modellverktøy.
Det andre undertrinnet er modelltreningsoperasjonen, som består av å kjøre flere iterasjoner for å forbedre vektene til de forskjellige lagene og den generelle nøyaktigheten til modellen.
Deretter må vi evaluere modellen, noe som gjøres ved å teste modellen med et delsett av data. Det vi allerede har beholdt for fremtidig testing og evaluering. Dette settet med data er ukjent for modellen. Vi kan deretter sammenligne modellutgangen med de kjente resultatene.
Når vi har fullført disse trinnene, kan vi bruke modellen som er opprettet og validere resultatene ved å utføre slutninger om mål. Tanken er å ta modellen i felt, gi den noen input og se om resultatene er riktige.
Programvare og
verktøy fra Microchip
Microchip har inngått samarbeid med flere tredjepartsselskaper, inkludert Edge Impulse, Motion Gestures og SensiML.
Vi støtter også populære rammeverk som TensorFlow Lite For Microcontrollers, som er en del av Microchip Harmony-rammeverket. TensorFlow Lite kan brukes til å lage modeller på tvers av hele Microchip-porteføljen, bortsett fra 8-bits komponenter per i dag. Microchip mikrokontrollere og mikroprosessorer er kompatible og støtter TensorFlow Lite.
Microchips mikrokontrollere og mikroprosessorløsninger støtter mange applikasjoner, som f.eks. smart innvevd maskinsyn. De passer også godt for prediktivt vedlikehold basert på enten vibrasjons-, effektmålings- eller lydovervåking. Mikrobrikkeporteføljen kan videre brukes i gestgjenkjenning og, kombinert med berøringsfunksjoner, kan det gjøre det enklere å styre menneske-maskingrensesnitt.
Microchip tilbyr høy-ytelses PCI-svitsjer som muliggjør sammenkobling av GPUer og hjelper med modelltrening.
Datainnsamling kan gjøres ved hjelp av mikrokontrollere, mikroprosessorenheter, FPGAer og sensorer. Alt tilgjengelig i Microchips portefølje.
Datavalidering og inferensoperasjon kan gjøres både på mikrokontrollere, mikroprosessorer og på FPGA-er.
Totalt sett gjør disse løsningene det enkelt å implementere ML ved hjelp av Microchip-porteføljen.
Når det gjelder programvare, er Microchips maskinlæringssenter et flott sted hvor våre nyeste løsninger presenteres.
Partnerverktøy
I tillegg til Microchip Harmony-rammeverket som støtter populære rammeverk, leveres maskinlæringsprogramvare, takket være flere partnerskap.
Et slikt partnerskap er med Edge Impulse, som har en komplett TinyML-rekke der vi kan samle inn data, bygge modellen og distribuere den. Denne partneren bruker TensorFlow Lite for mikrokontrollere. En av de største fordelene her er at Edge Impulses kode er helt åpen kildekode og royaltyfri.
En annen partner er Motion Gestures, som spesialiserer seg på gestgjenkjenning som kan brukes til å bygge menneske-maskingrensesnitt. Dette verktøyet kan hjelpe med å lage og implementere gester på få minutter, og redusere programvareutviklingstiden – det gir også tilfredsstillende resultater for gestgjenkjenninger som nærmet seg 100 % gjenkjennelse i tester.
Det er to måter å bruke dette verktøyet på, enten med berøring, den klassiske måten eller bevegelse, ved hjelp av noen IMU-sensorer.

Komme i gang
Microchip tilbyr flere sett for å få utviklere i gang innen AI og ML. På mikrokontrollersiden, SAMD21 ML, SAMD21 Machine Learning-evalueringssett med en TDK-sensor. En annen variant bruker Bosch AMU.
På gestbevegelsessiden har vi en demo med SAMC21 Xplained Pro pluss en QTouch-berøringsplate, et av verktøyene du kan begynne å implementere ML-gestgjenkjenningsapplikasjonen din med.
IGaT er et grafikk- og berøringskort som også bruker ML, med klar fastvare som har gestgjenkjenningsdemoen i tillegg til mange andre demoer for biler, hjemme, underholdning og andre.
Adafruit EdgeBadge - TensorFlow Lite for Microcontrollers er et annet sett som bruker TensorFlow Lite direkte.
Det har en 2-tommers TFT skjerm. EdgeBadge kan brukes av Arduino-miljøet. Flere eksempler er lagt frem, slik som Sinusbølge Demo, Gest Demo og «Micro Speech Demo».
På den avanserte siden har PolarFire-videosettet et dobbeltkameragrensesnitt, MIPI-grensesnitt, HDMI-grensesnitt, og kommer med 2 GB DDR, 4 SDRAM, et USB2UART-grensesnitt og 1 GB SPI-blits.
PolareFire video kit har et dobbel kameragrensesnitt, MIPI grensesnitt, HDMI grensesnitt, og kommer med 2GB DDR, 4 SDRAM, et USB2 UART grensesnitt, og 1GB SPI flash.
Dette settet kommer ferdig til bruk, ut-av-esken, med en objektdetekterings-demo med bruk av eller basert på en ML modell.
For mer informasjon: https://www.microchip.com/en-us/education/developer-help/learn-solutions/machine-learning
Om forfatteren: Adil Yacoubi er EMEA Sr. Technical Marketing Engineer, Microchip Technology Inc.





























