
Persistent minne i kunstig intelligens og maskinlæringsapplikasjoner
Datasentre burde nyttiggjøre seg såkalt persistent, eller vedvarende minne for å eliminere flaskehalser og øke ytelsen innen kunstig intelligens og maskinlæring.
Denne artikkelen er 2 år eller eldre
I dagens datasentre er begrenset minnekapasitet og I/O-ytelsen til masselageret de to største årsakene til flaskehalser. Disse to smertepunktene har historisk sett blitt oppfattet som forskjellige databehandlingskonsepter: minne er en midlertidig lagring av kode og data som støtter en applikasjon som kjører, mens harddisker og annen vedvarende lagring oppbevarer data på lang sikt. Når et program trenger å få tilgang til data fra harddisken (som ofte skjer med store datasett som ikke kan holdes i minnet), gir den langsomme tilgangen en betydelig ulempe for programmets ytelse. Innføringen av vedvarende minne har markert et vendepunkt i den tradisjonelle datasenterhukommelsen og lagringshierarkiet, gjennom muligheten for en ny enhetlig hyperkonvergert arkitektur som dramatisk akselererer ytelsen til lagringsservere for bedrifter.

Fremveksten av AI- og ML-applikasjoner
Eksplosjonen av data har resultert i enorm vekst i kunstig intelligens (AI) og maskinlæring (ML) -applikasjoner, men tradisjonelle systemer er ikke designet for å møte utfordringen med å få tilgang til disse store datasettene. Den største hindringen for AI- og ML-applikasjoner som kommer inn i IT-mainstream, er å redusere den totale tiden for oppdagelse og innsikt basert på data-intensiv ETL (Extract, Transform, Load), samt sjekkpunktoppgaver. AI og ML skaper svært krevende I/O- og beregningsytelse for GPU-akselerert ETL. Varierende I/O- og beregningsytelse er drevet av båndbredde og forsinkelse. Den avanserte dataanalysen som AI- og ML-applikasjoner trenger, krever systemer med høy båndbredde og laveste mulige forsinkelse.
Prosesseringsbehov
Ifølge International Data Corporation (IDC) Worldwide Artificial Intelligence Spending Guide, vil investeringer i AI- og ML-systemer nå USD 97,9 milliarder i 2023, mer enn to og en halv ganger de USD 37,5 milliarder som ble brukt i 2019. Til gjengjeld vil veksten i dataprosesseringen som trengs for å holde tritt med denne økningen være eksponensiell. Konvensjonelle minneløsninger i dag mangler den vitale komponenten som kan svare på denne etterspørselen: Nonvolatilitet, også når parallelle arkitekturer blir designet for å møte fremtidige databehov. Mens disse arkitekturene videreutvikles risikerer datasentrene å tape millioner av dollar grunnet effekttap. Derfor eksisterer det et umiddelbart behov for nonvolatile minner.
Flytter nonvolatile minner nærmere CPUen

Såkalt «checkpointing» er en prosess der tilstanden til nettet som trenes lagres for å sikre at resultatet av innlærte data ikke går tapt. Checkpointing er en spesiell utfordring for AI- og ML-applikasjoner fordi den sløser prosessorkapasitet og brenner mye strøm, uten å gi fordeler for selve applikasjonen direkte. Behandling i andre noder kan også stoppe opp når du skriver data til et sentralt lager. Operasjonen er også skriveintensiv, og forverrer problemet i noen situasjoner, da konvensjonelle lager, som harddisker er ineffektive når data skrives til dem.
Ettersom checkpointing til et sentralt minne kan redusere hastigheten for innsikt i AI- og ML-applikasjoner betydelig, beveger ingeniører nonvolatilt minne nærmere CPU-en for å minimere effekten av denne viktige prosessen. Dette gir en bedre balanse mellom data og prosessering, slik at systemet kan levere det totale produksjonsbehovet.
NVDIMMs i AI- og ML-applikasjoner
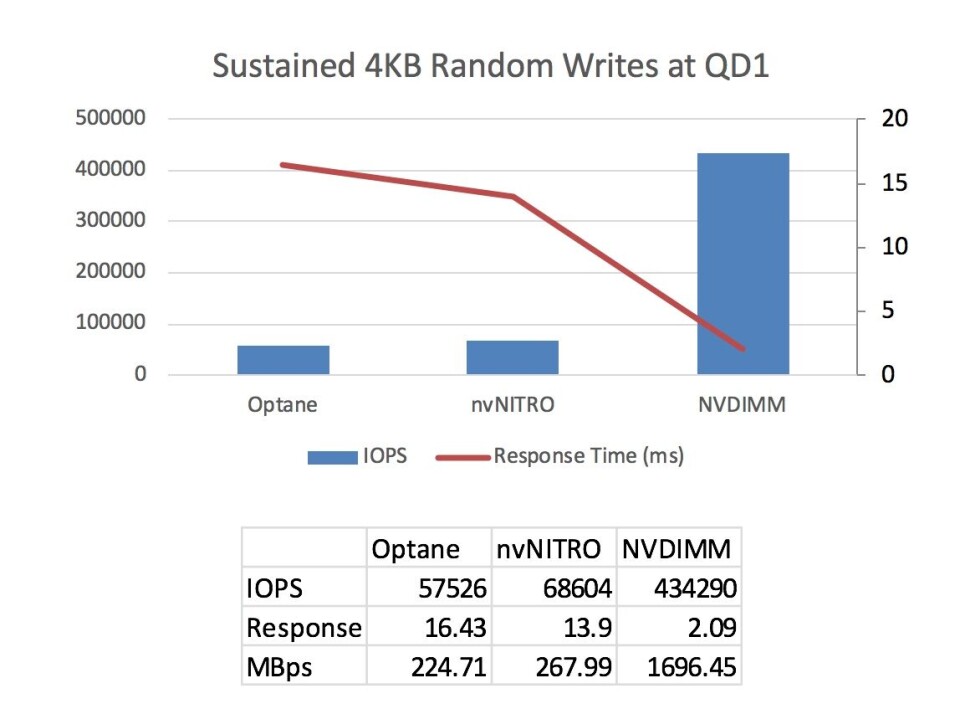
Vedvarende minne, i form av NVDIMM (en nonvolatil dual-inline minnemodul), brukes til å øke ytelsen til applikasjoner som er følsomme for skriveforsinkelse (latens), noe som gir en persistent lagringsmodell med DRAM-ytelse. Datasentre har en unik mulighet til å dra nytte av NVDIMM-er for å oppnå lav latens og økte ytelseskrav for AI- og ML-applikasjoner, uten store teknologisprang.
Når NVDIMMer kobles til en server, blir de kartlagt av BIOS som en del av persistent minne innenfor hovedminnet. Applikasjonen står da fritt til å bruke dette persistente minnet til høyhastighets checkpointing. Alternativet er den tradisjonelle tilnærmingen der kontrollpunktdataene overføres gjennom I/O-stakken, over NVMe og deretter lagres til en SSD. Dette systemet medfører latensulemper for I/O-stakken og NAND Flash.
NVDIMM-er er en ideell løsning for høyytelses AI- og ML-servere. Dataintensive ETL- og checkpointing-oppgaver kan anvende det persistente minneområdet i hovedminnet, slik at de kan operere med DRAM-forsinkelser (<100ns) og DRAM-båndbredde (25,6 GB/s).
NVDIMM-er brukes gjerne til å akselerere checkpointing for AI-applikasjoner, men kan også brukes til ML for å øke ytelsen og beskytte data som samles inn av algoritmer. GPU-konfigurerte lagringsservere kjører algoritmer som er en del av simulering og ML. NVDIMM-er brukes til å beskytte GPU-serverne mot å miste simuleringsdata. Typiske størrelser på algoritmedatasett varierer fra kilobytes (kB) til terabytes (TB), og tapte data vil føre til behov for å starte arbeidet på nytt. Når fire servere er konfigurert med NVDIMM-er, kan datasettstørrelser opp til 1 TB bruke persistent minne, i motsetning til tradisjonell lagring, for å forbedre ytelsen dramatisk uten risiko for å miste data.
Den vanligste metoden som brukes til å behandle AI-, ML- og simuleringsdatasett (som alle har lignende egenskaper) er at datasettene kommer gjennom nettverket via InfiniBand eller Ethernet til AI/ML-serveren og deretter caches i SSD for å eliminere risikoen for datatap . Deler av datasettene blir deretter flyttet til DRAM av GPU der beregningene kan utføres. Et eksempel på denne prosessen kan være å utføre beregninger på et datasett for å avgjøre om dataene representerer et bilde av en hund eller katt. Når beregningen er fullført, sendes svaret tilbake til nettverket. Hvis det oppstår et systemkrasj under denne prosessen, går alle beregninger tapt. Ved å bytte til NVDIMM-er kan denne prosessen strømlinjeformes dramatisk. Det er ikke nødvendig å cache innkommende datasett i SSD-ene. Datasettene kan flyttes direkte til DRAM der GPU umiddelbart kan starte beregningene. Svaret på om et bestemt datasett representerer et bilde av en hund eller katt kan komme mange ganger raskere. Samtidig er det ingen risiko for å miste datasettene eller beregningene, fordi NVDIMM-ene er persistente.
NVDIMM-er er ikke bare godt egnet for AI- og ML-applikasjoner, de kan også brukes i økonomiske applikasjoner, som ofte kalles FinTech. FinTech-applikasjoner krever høy ytelse (reduserer ventetid og øker transaksjonshastigheter) fordi tid er penger. Behandlede transaksjoner må logges synkront før neste transaksjon kan startes. Denne synkrone funksjonen, som også er kritisk for revisjon, skaper en betydelig flaskehals for mange systemer, noe som reduserer transaksjonshastigheten.
Ved å bruke NVDIMM-er kan den nåværende prosessen med å logge data til SATA- eller NVMe SSDer elimineres. I stedet for å sende loggdata via I/O til Flash SSD, kan loggdataene settes direkte i høyhastighets DRAM, gjort persistente ved bruk av NVDIMM. NVDIMM-ene gjør det mulig for systemet å starte neste transaksjon i tillit til at den forrige transaksjonen er logget på et sikkert sted uten risiko for tap av data.
Mens NVDIMM-er har eksistert i mer enn et tiår, blir fordelene ved å bruke denne typen persistent minne for AI- og ML-applikasjoner fortsatt utforsket av ulike sektorer, fra bank og detaljhandel til diskret produksjon, prosessindustri, helsetjenester og profesjonelle tjenester. Økosystemet av støtte for NVDIMM-er, inkludert operativsystemer, maskinvareaktivering og JEDEC-standardisering, er et resultat av at mange selskaper har jobbet sammen for å ta i bruk persistent minne. Tilgjengeligheten av NVDIMM-er sammenfaller med fremveksten av AI og ML og gir en ideell måte å øke systemytelsen på.





























